Our understanding about genetics is rapidly changing. The goal of this article is to provide an overview of the basics of and new developments in medical genetics—a Genetics 101 primer for 2008. In this article we review the structure and function of the genes, how genes are packaged, gene replication, gene mutations, and the different modes of inheritance.
Our understanding about genetics is rapidly changing. The goal of this article is to provide an overview of the basics of and new developments in medical genetics—a Genetics 101 primer for 2008. In this article we review the structure and function of the genes, how genes are packaged, gene replication, gene mutations, and the different modes of inheritance.
Basic gene structure
The basic building blocks for genes, the genetic encyclopedia, is “written” using four deoxyribonucleotides (A, G, T, C: adenylic acid, guanylic acid, thymidylic acid, and cytidylic acid). A single strand of DNA is composed of a string of these deoxyribonucleotides linked together on a sugar phosphate backbone ( Fig. 1 ) . The 3′ carbon of one of the sugars is attached to a phosphate, which is in turn linked to the 5′ carbon on the next nucleotide. The complete DNA is formed when two strands of DNA are joined together to look like a ladder twisted in the form of a double helix.
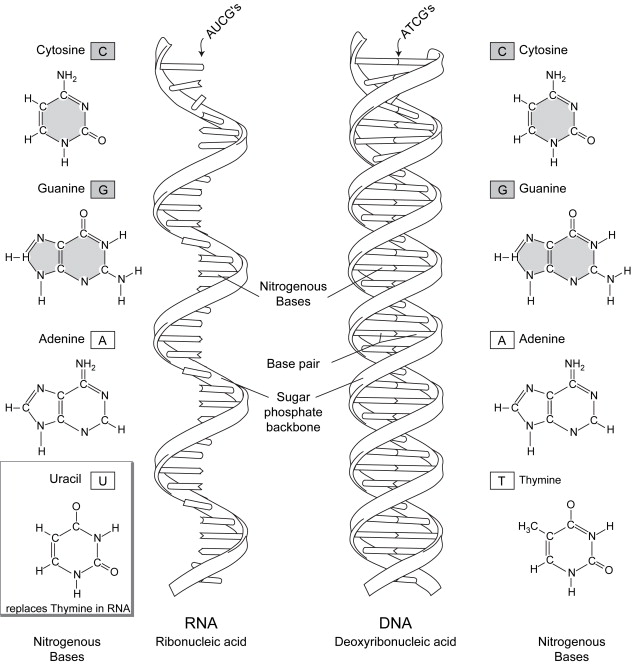
The link between the two strands that form the complete DNA is caused by hydrogen bonding between the nucleotides on each of the opposite strands of DNA. This binding is specific: A on one strand always binds to T on the complementary strand with two bonds, and G always binds to C on its complementary strand with three bonds. This combination of A-T and G-C is referred to as a base pair. The order of these base pairs on the genes provides the precise blueprint for the entire structure of the organism. There are approximately 3 billion of these base pairs in the human genome. Each human cell contains 6.6 billion bases (A, C, G, or T) or approximately 5 ft of DNA. The adult body contains approximately 10 trillion cells, so with 5 ft in each of 10 trillion cells, there is enough DNA to reach from Earth to the sun 90 times.
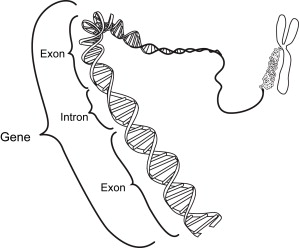
Most genetic research has focused on genes that code for protein products. Most of the known gene sequences in humans that code for proteins are discontinuous: coding regions (areas that actually code for the proteins) called exons, which are usually split by noncoding regions called intervening sequences (introns) ( Fig. 2 ). Although it was originally thought that there were 50 to 100,000 protein coding genes in the human genome, based on the Human Genome Project it seems that only 25 to 30,000 genes encode for proteins . It is currently thought that only 1% to 2% of the human genome codes for proteins.
DNA packaging
Because each cell contains all of the genetic material, the DNA must be packaged to fit into the nucleus of each cell, be protected against damage from external factors (eg, radiation), be available for replication and transcription, and be accessible for repairs. The DNA in the nucleus is set in a histone backbone and then spooled (like thread) before being stacked in groups of eight ( Fig. 3 ) . These stacks of histone-rich spooled DNA are subsequently compacted further to form each of the 46 chromatids. Each of the chromatids is composed of two asymmetric arms (the short arm is called the p arm; the longer is the q arm) joined at the centromere. A chromosome is composed of two chromatids. It is important to understand that one of the chromatids on each chromosome is of maternal origin, whereas the opposite is of paternal origin. The diploid genome consists of 22 pairs of autosomes numbered from largest to smallest and one pair of sex chromosomes (X/Y or XX). (Although chromosome number 22 is larger than number 21, it was decided to keep it this way because geneticists were used to calling Down syndrome trisomy 21.) A karyotype is composed of these 23 pairs of chromatids arranged in order ( Fig. 4 ).
Gene expression
Each gene encodes a particular protein that has a specific cellular function. Initially, in the nucleus, the DNA is copied in a process called transcription into a single strand of messenger RNA (mRNA) ( Fig. 5 ). The mRNA is similar to DNA with four nucleotide bases, with the exception of uracil (U), which replaces T in the sequence. The mRNA is immediately modified to excise the introns or noncoding sequences and cap the 3′ and 5′ ends. This mRNA then translocates into the cytoplasm of the cell to contact the ribosome (protein producing mechanism). The ribosome then reads the mRNA sequence and, in a process called translation, produces a chain of amino acids that precisely mirrors the information found in the mRNA. The ribosome begins protein translation at the initiation codon (AUG) and then reads packages of three nucleotides from the mRNA at a time ( Fig. 6 ). Each of these triplets, called a codon, translates into a specific amino acid. There is a total of 20 different amino acids, which are added in sequence to the growing polypeptide chain according to the codons ( Fig. 7 ). The code is “degenerate” because in most cases there are several different codons for each amino acid (eg, phenylalaline is encoded by TTT or TTC). Finally, a terminator or stop codon (UAG, UAA, or UGA) cannot be decoded into an amino acid, so protein synthesis terminates.
As an example of the relationship between the DNA, mRNA, and the amino acid, a DNA triplet code of TAT is transcribed into an mRNA codon of AUA, which is subsequently translated into the amino acid isoleucine. The polypeptide chains once formed undergo folding and other posttranslational modifications to form mature proteins. Subsequently, different peptide chains can combine to create a novel protein (eg, adult hemoglobin made of four different globins: two alpha chains plus two beta chains).
DNA packaging
Because each cell contains all of the genetic material, the DNA must be packaged to fit into the nucleus of each cell, be protected against damage from external factors (eg, radiation), be available for replication and transcription, and be accessible for repairs. The DNA in the nucleus is set in a histone backbone and then spooled (like thread) before being stacked in groups of eight ( Fig. 3 ) . These stacks of histone-rich spooled DNA are subsequently compacted further to form each of the 46 chromatids. Each of the chromatids is composed of two asymmetric arms (the short arm is called the p arm; the longer is the q arm) joined at the centromere. A chromosome is composed of two chromatids. It is important to understand that one of the chromatids on each chromosome is of maternal origin, whereas the opposite is of paternal origin. The diploid genome consists of 22 pairs of autosomes numbered from largest to smallest and one pair of sex chromosomes (X/Y or XX). (Although chromosome number 22 is larger than number 21, it was decided to keep it this way because geneticists were used to calling Down syndrome trisomy 21.) A karyotype is composed of these 23 pairs of chromatids arranged in order ( Fig. 4 ).
Gene expression
Each gene encodes a particular protein that has a specific cellular function. Initially, in the nucleus, the DNA is copied in a process called transcription into a single strand of messenger RNA (mRNA) ( Fig. 5 ). The mRNA is similar to DNA with four nucleotide bases, with the exception of uracil (U), which replaces T in the sequence. The mRNA is immediately modified to excise the introns or noncoding sequences and cap the 3′ and 5′ ends. This mRNA then translocates into the cytoplasm of the cell to contact the ribosome (protein producing mechanism). The ribosome then reads the mRNA sequence and, in a process called translation, produces a chain of amino acids that precisely mirrors the information found in the mRNA. The ribosome begins protein translation at the initiation codon (AUG) and then reads packages of three nucleotides from the mRNA at a time ( Fig. 6 ). Each of these triplets, called a codon, translates into a specific amino acid. There is a total of 20 different amino acids, which are added in sequence to the growing polypeptide chain according to the codons ( Fig. 7 ). The code is “degenerate” because in most cases there are several different codons for each amino acid (eg, phenylalaline is encoded by TTT or TTC). Finally, a terminator or stop codon (UAG, UAA, or UGA) cannot be decoded into an amino acid, so protein synthesis terminates.
As an example of the relationship between the DNA, mRNA, and the amino acid, a DNA triplet code of TAT is transcribed into an mRNA codon of AUA, which is subsequently translated into the amino acid isoleucine. The polypeptide chains once formed undergo folding and other posttranslational modifications to form mature proteins. Subsequently, different peptide chains can combine to create a novel protein (eg, adult hemoglobin made of four different globins: two alpha chains plus two beta chains).
Related posts:




Stay updated, free articles. Join our Telegram channel

Full access? Get Clinical Tree


