such that the probability of a false positive is α and the power to detect the largest clinically relevant difference in event rates is 1 − β. Assuming that both the treatment and control arms consist of independent groups of patients, Pocock [21] suggests a Chi-squared test without continuity correction for testing the above hypothesis.
Based on this test, the required sample size for each arm is given by
![$$ N=\frac{{\left({Z}_{1-\alpha /2}+{Z}_{1-\beta}\right)}^{{}^2}\left[{p}_c\left(1-{p}_c\right)+{p}_t\left(1-{p}_t\right)\right]}{{\left({p}_t-{p}_c\right)}^{{}^2}}, $$](/wp-content/uploads/2016/07/A83119_2_En_4_Chapter_Equb.gif) where Z q is the qth quantile of the standard normal distribution. Table 4.1 provides the most commonly used values of Z q . Note that several other methods can be used to determine sample size in this situation, and the above formula is only presented as a general guideline.
where Z q is the qth quantile of the standard normal distribution. Table 4.1 provides the most commonly used values of Z q . Note that several other methods can be used to determine sample size in this situation, and the above formula is only presented as a general guideline.
Table 4.1
Commonly used values of Z q for sample size calculations
Type I error (α) | Type II error (β) | ||||
|---|---|---|---|---|---|
0.05 | 0.025 | 0.01 | 0.80 | 0.90 | |
q | 0.975 | 0.9875 | 0.995 | 0.80 | 0.90 |
Z q | 1.96 | 2.24 | 2.58 | 0.84 | 1.28 |
As an example, suppose it is known that the control treatment has a 30 % response rate and it is of clinical interest to detect a 20 % increase (or a 50 % response rate) in the new treatment with a 90 % power. The investigator would also like to ensure that the probability of a false positive is 5 %. Using the above formula, each arm of the study requires 121 patients.
Continuous Outcome
A continuous outcome takes a value that ranges between negative and positive infinity in theory. An example is the change in PSA level 3 months after drug administration in a prostate cancer trial. For continuous outcome, the goal is to determine if there is a difference in outcome means between the arms. To determine the number of patients in the trial, the investigator must first specify the expected means in the control and treatment arms, given by μc and μt respectively. The standard deviation of the outcome in the control group is denoted by σ. Using this notation, the required sample size is calculated based on testing the hypothesis
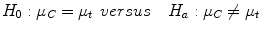 such that the probability of a false positive is α and the power to detect the largest clinically relevant difference in means is 1 − β. Assuming that both the treatment and control arms consist of independent groups of patients and the standard deviation of the outcome in the control arm is similar to that in the treatment arm, a two-sample t-test is often used to test the above hypothesis. Based on this test, the required sample size for each arm is given by
such that the probability of a false positive is α and the power to detect the largest clinically relevant difference in means is 1 − β. Assuming that both the treatment and control arms consist of independent groups of patients and the standard deviation of the outcome in the control arm is similar to that in the treatment arm, a two-sample t-test is often used to test the above hypothesis. Based on this test, the required sample size for each arm is given by
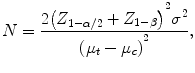 where Z q is the qth quantile of the standard normal distribution. Note that this formula is suitable for a relatively large N, but may not apply for small sample sizes.
where Z q is the qth quantile of the standard normal distribution. Note that this formula is suitable for a relatively large N, but may not apply for small sample sizes.
As an example, the outcome is the change of glomerular filtration rate (GFR) after 5 years in a kidney trial. Suppose that the change (decline) of GFR is 10 ml/min/1.73 m2 in the control arm, with a standard deviation of 20. It is of clinical interest to detect a 5 ml/min/1.73 m2 decline in the new treatment with 90 % power. The investigator would also like to ensure that the probability of a false positive is 5 %. Using the above formula, each arm of the study requires 337 patients.
Survival Outcomes
A survival outcome, or more generally a time-to-event outcome, measures the time to the occurrence of certain clinical events in patients from their enrollment into the trial. In most cancer clinical trials, the primary outcome is patient survival, that is, time to mortality, and the most common objective is to evaluate the effect of a new treatment on prolonging patient survival.
Survival outcomes are usually subject to censoring. For patients who are alive at the end of the trial or lost to follow-up during the trial course, their exact deceased times are unknown but larger than the last follow-up time. The analysis of survival outcomes in a clinical trial is typically to compare hazard rates or median survival times between treatment arms. Hazard is the risk of developing the event at an instant in time, and median survival time is the time at which half of the patients are event-free. These two parameters are equivalent when the survival curve follows an exponential shape. Furthermore, the hazard ratio between two treatment arms may be constant over time, leading to the so called proportional hazards. Thus, without loss of generality, we focus on the sample size calculation for comparing hazard rates.
< div class='tao-gold-member'>
Only gold members can continue reading. Log In or Register to continue
Related posts:
 Diet and GU Cancers
Diet and GU Cancers
 Life After Urological Cancer – Psychological Issues
Life After Urological Cancer – Psychological Issues
 Genetics and Genito-Urinary Cancer
Castrate Resistant Prostate Cancer: Systemic Chemotherapy and a System Problem
Genetics and Genito-Urinary Cancer
Castrate Resistant Prostate Cancer: Systemic Chemotherapy and a System Problem
 Renal Failure, Dialysis and Transplantation: In the Management of Renal Cell Carcinoma (Solitary Kidney and Bilateral Renal Tumours)
Renal Failure, Dialysis and Transplantation: In the Management of Renal Cell Carcinoma (Solitary Kidney and Bilateral Renal Tumours)
 High Intensity Focused Ultrasound (Hifu) in Prostate Cancer
High Intensity Focused Ultrasound (Hifu) in Prostate Cancer
Stay updated, free articles. Join our Telegram channel

Full access? Get Clinical Tree


