Fig. 1.1
Illustration of the sites of cellular connections and the adhesion molecules found at the interface between the cell and a basement membrane and between cells. Diagrammatic illustration of the four types of receptor found in a cell: 1 cytoplasmic, 2 Ion channel, 3 enzyme linked, 4 G protein linked. (*represents receptor ligand)
Secondary Messengers
Cyclic AMP, IP3/DAG, and Ca2+ Ions
Cyclic adenosine monophosphate (cAMP) is derived from ATP. It functions in intracellular signal transduction (e.g., effects of hormones like glucagon and adrenaline). It activates protein kinases and regulates the passage of Ca2+ through ion channels. The G-protein–coupled transmembrane receptors (GPCs) form one of the largest families of cell receptors. G-protein complexes activate inner membrane- bound phospholipase complexes. These in turn cleave membrane phospholipid— polyphosphoinositide (PIP2)—into inositol triphosphate (IP3) (water soluble) diacylglycerol (DAG) (lipid soluble). The former interacts with gated ion channels in the ER, causing a rapid release of Ca2+, and the latter remains at the membrane, activating a serine/threonine kinase, protein kinase C.
Protein Phosphorylation
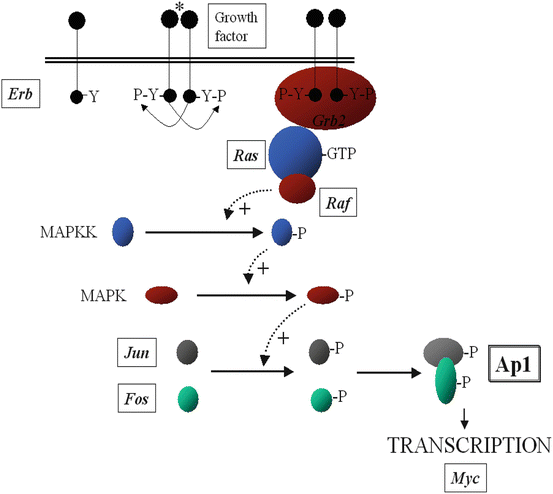
Although phosphorylation of the cytoplasmic secondary messengers is often a consequence of secondary activation of cAMP, Ca2+ and DAG, the principal route for the protein phosphorylation cascades is from the dimerization of surface protein kinase receptors. The tyrosine kinase receptors phosphorylate each other when ligand binding brings the intracellular receptor components in to close proximity. The inner membrane and cytoplasmic targets of these activated receptor complexes are Ras, protein kinase C, and ultimately the mitogen-activated protein (MAP) kinase, Janus Stat pathways (family of intracellular tyrosine kinase), or phosphorylation of IκB, causing it to release its DNA-binding protein nuclear factor κB (NF-κB). These intracellular signalling proteins usually contain conserved noncatalytic regions called the Serc homology regions 2 and 3 (SH2 and SH3). The SH2 region binds to phosphorylated tyrosine. The SH3 domain has been implicated in the recruitment of intermediates, which activate Ras proteins. Like G proteins, Ras (and its homologous family members Rho and Rac) switches between inactive GDP-binding state and active GTP-binding states. This starts a phosphorylation cascade of the MAP kinase, Janus-Stat protein pathways, which ultimately activate a DNA binding protein. This protein undergoes a conformational change, enters the nucleus, and initiates transcription of specific genes.
Free Radicals
A free radical is any atom or molecule containing one or more unpaired electrons, making it more reactive than the native species. They have been implicated in a large number of human diseases. The hydroxyl (OHO) radical is by far the most reactive species, but the others can generate more reactive species as breakdown products. When a free radical reacts with a nonradical, a chain reaction ensues resulting in direct tissue damage by lipid peroxidation of membranes. Hydroxyl radicals can cause mutations by attacking DNA. Interestingly ionising radiation used in cancer treatment can activate this mechanism by the interaction with water molecules.
Superoxide dismutases O2O (SOD) convert superoxide to hydrogen peroxide. Glutathione peroxidases are major enzymes that remove hydrogen peroxide generated by SOD in cytosol and mitochondria. Free radical scavengers bind reactive oxygen species (ROS). α-Tocopherol, urate, ascorbate, and glutathione remove free radicals by reacting in a direct and noncatalytic way. There is a growing evidence that cardiovascular diseases and cancer can be prevented by a diet rich in substances that diminish oxidative damage. Principal dietary antioxidants include vitamins C and E, β-carotene, and flavonoids.
Heat Shock Proteins
Heat shock proteins (HSPs) are induced by heat shock and other chemical and physical stresses [20], and their functions include the export of proteins in and out of specific cell organelles, acting as molecular chaperones (the catalysis of protein folding and unfolding), and the degradation of proteins (often by ubiquitination pathways). The unifying feature, which leads to the activation of HSPs, is the accumulation of damaged intracellular protein. Tumors have an abnormal thermo-tolerance, which is the basis for the observation of enhanced cytotoxic effect of chemotherapeutic agents in hyperthermic subjects. The HSPs are expressed in a wide range of human cancers and are implicated in cell proliferation, differentiation, invasion, metastasis, cell death, and immune response [20]. Although HSP detection by immunocytochemistry has been an established practice, serum detection of HSP and its antibodies is still a new research area. Various types of HSP have been demonstrated in urogenital cancers including kidney, prostate, and bladder. For example, HSP27 expression in prostate cancer indicates poor clinical outcome [21, 22].
Programmed Cell Death
In necrotic cell death external factors damage the cell with influx of water and ions leading to the swelling and rupture of cellular organelles. Cell lysis induces acute inflammatory responses in vivo (Table 1.1). In apoptosis, cell death occurs through the deliberate activation of constituent genes whose function is to cause their own demise. Necrosis lacks the features of apoptosis and is an uncontrolled process. Another process is autophagy (self eating) which is lysosome mediated catabolic process. Apoptotic cell death has the following characteristic morphological features:
Table 1.1
Contrasting morphological features of necrotic and apoptotic cell death
Necrosis | Apoptosis |
|---|---|
Swelling of the cell | Cellular shrinkage |
Ruptured plasma membrane | Intact plasma membrane |
Intact nucleus | Condensation of chromatin and mDNA damage |
Nonspecific proteolysis | Specific coordinated proteolysis |
Swelling of cell organelles | Normal size cell organelles |
Occurs because no energy available | Energy is required |
Chromatin aggregation, with nuclear and cytoplasmic condensation into distinct membrane-bound vesicles, which are termed apoptotic bodies
Organelles remain intact
Cell blebs (which are intact membrane vesicles)
No inflammatory response
Cellular blebs and remains are phagocytised by adjacent cells and macrophages
Molecular Biology of Apoptosis
Apoptosis is a highly regulated mechanism of cell death which helps in development process and getting rid of damaged cells. Most cells rely on a constant supply of survival signals without which they will undergo apoptosis. Neighbouring cells and the extracellular matrix provide these signals. Cancer, autoimmunity, and some viral illnesses are associated with inhibition of apoptosis and increased cell survival. Metastatic tumor cells circumvent the normal environmental cues for survival and can survive in foreign environments. The molecular basis of steps of apoptosis—death signals, genetic regulation, and activation of effectors—has been identified [23]. Apoptosis requires energy (ATP), and several Ca2+ – and Mg2+ dependent nuclease systems are activated, which specifically cleave nuclear DNA at the interhistone residues. This involves the enzyme cysteine-containing aspartase-specific protease (CASPASE), which activates the caspase-activated DNAase (CAD)/inhibitor of CAD (ICAD) system. Apoptotic signals affect mitochondrial permeability, resulting in reduction in the membrane potential and mitochondrial swelling. The apoptotic trigger cytochrome c is released from mitochondria into cytosol [24].
Bcl-2, p53, and the Proapoptotic Gene Bax
Several proteins including members of the Bcl-2 family regulate mitochondrial permeability. Bcl-2 (24 kd) is associated with the internal membrane of the mitochondria and the nucleus. Bcl-2 suppresses apoptosis by directly preventing mitochondrial permeability and by interacting with other proteins [25]. The other gene that has been studied extensively is the tumor suppressor gene p53. It has an important role in cell cycle regulation and acts as a transcription factor that controls other gene products. Normal wild-type p53 limits cell proliferation after DNA damage by arresting the cell cycle or activating apoptosis [25]. Also, p53 has a complex role in chemosensitivity; it can increase apoptosis or arrest growth, thereby increasing drug resistance [26]. Drugs like taxanes and vinca alkaloids induce apoptosis independent of p53, as they do not damage DNA [26]. The proapoptotic gene bax has also been extensively investigated. In contrast to Bcl-2, bax is a promoter of apoptosis. Different pathways are discussed later.
Molecular Genetics
Genetic information is stored in the form of double-stranded deoxyribonucleic acid (DNA). Each strand of DNA is made up of a deoxyribose-phosphate backbone and a series of purine [adenine (A) and guanine (G)] and pyrimidine [thymine (T) and cytosine (C)] bases of the nucleic acid. For practical purposes, the length of DNA is generally measured in numbers of base pairs (bp). The monomeric unit in DNA (and in RNA) is the nucleotide, which is a base joined to a sugar-phosphate unit. The two strands of DNA are held together by hydrogen bonds between the bases. There are only four possible pairs of nucleotides: TA, AT, GC, and CG. The two strands twist to form a double helix with major and minor grooves, and the large stretches of helical DNA are coiled around histone proteins to form nucleosomes and are further condensed into the chromosomes that are seen at metaphase.
Human Chromosomes
The nucleus of each diploid cell contains 3 × 109 bp of DNA (Fig. 1.2). Chromosomes are massive structures containing one linear molecule of DNA that is wound around histone proteins, which are further wound to make up the structure of the chromosome itself. Diploid human cells have 46 chromosomes, 23 inherited from each parent; 22 pairs of autosomes, and two sex chromosomes (XX female and XY male). The chromosomes can be classified according to their size and shape, the largest being chromosome 1. The constriction in the chromosome is the centromere, which may be in the middle of the chromosome (metacentric) or at one extreme end (acrocentric). The centromere divides the chromosome into a short arm (p arm) and a long arm (q arm). In addition, chromosomes can be stained when they are in the metaphase stage of the cell cycle and are very condensed. The stain gives a different pattern of light and dark bands that is diagnostic for each chromosome. Each band is given a number, and gene mapping techniques allow genes to be positioned within a band within an arm of a chromosome. During cell division, mitosis, each chromosome divides into two so that each daughter nucleus has the same number of chromosomes as its parent cell. During gametogenesis, however, the number of chromosomes is halved by meiosis.
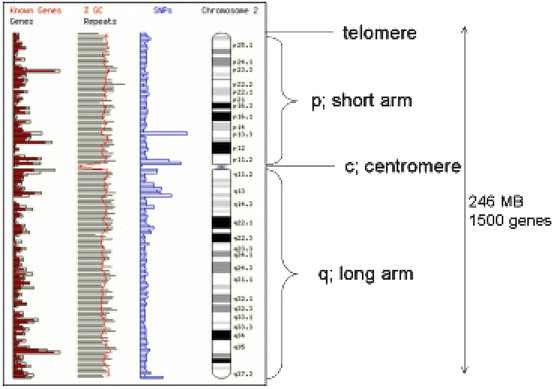
Fig. 1.2
Chromosome structure (ch7) showing the position of the centromere telomeres, and short (p) and long arms (q). A G-banding pattern is shown and how this maps to known sites of genes and genetic markers such as single nucleotide polymorphisms (SNPs) and the CG rich island, which are characteristic of gene control elements
Telomeres and Immortality
The ends of eukaryotic chromosomes, telomeres, do not contain genes but rather many repeats of a guanine-rich hexameric sequence TTAGGG. Telomeres are specialized DNA structures that protect the ends of chromosome from fusion and recombination events [27]. Telomerase is a ribonucleoprotein that is necessary to repair the telomeric losses. Replication of linear chromosomes starts at coding sites (origins of replication) within the main body of chromosomes and not at the two extreme ends. The extreme ends are therefore susceptible to single-stranded DNA degradation back to double-stranded DNA. As a consequence of multiple rounds of replication, the telomeres shorten, leading to chromosomal instability and ultimately cell death. Stem cells have longer telomeres than their terminally differentiated daughters. However, germ cells replicate without shortening of their telomeres because of telomerase. Most somatic cells (unlike germ and embryonic cells) switch off the activity of telomerase after birth and die as a result of apoptosis [28]. Many cancer cells, however, reactivate telomerase, contributing to their immortality. Conversely, cells from patients with progeria (premature ageing syndrome) have extremely short telomeres. Telomerase activity is detected in nearly all cancer cells [29]. Likewise, prostate cancer but not normal prostate or benign prostatic hyperplasia (BPH) tissue, expresses telomerase activity [30]. Inhibition of telomerase with DNA-damaging chemotherapy drugs seems a possibility in prostate cancer [31]. Telomerase from exfoliated transitional cell carcinoma cells has been used as a urinary marker in bladder cancer [32].
The Mitochondrial Chromosome
The mitochondrial chromosome is a circular DNA (mtDNA) molecule (16.5 kb), and every base pair makes up part of the coding sequence. These genes principally encode proteins or RNA molecules involved in mitochondrial function. These proteins are components of the mitochondrial respiratory chain involved in oxidative phosphorylation (OXPHOS) producing ATP. The mtDNA mutations are generated during OXPHOS through pathways involving reactive oxygen species (ROS), and unlike the nucleus these mutations may accumulate in mitochondria because they lack protective histones [33]. There are many reasons to believe that the biology of mitochondria could drive tumorigenesis: (1) mitochondria generate ROS, which in high concentrations are highly mitogenic to the nuclear and mitochondrial genomes; (2) mitochondria have a key role in effecting apoptosis; and (3) mitochondria accumulate in high density in some malignant tumors (renal cell carcinoma) as tumor cells have lesser dependence on mitochondria for their oxidative phosphorylation [34]. The mutations of mtDNA have been demonstrated in renal cell, prostate, and bladder cancers.
Genes
A gene is a portion of DNA that contains the codes for a polypeptide sequence. Three adjacent nucleotides (a codon) code for a particular amino acid, such as AGA for arginine, and TTC for phenylalanine. There are only 20 common amino acids, but 64 possible codon combinations that make up the genetic code. This means that more than one triplet encodes for some amino acids; other codons are used as signals for initiating or terminating polypeptide-chain synthesis. Genes consist of lengths of DNA that contain sufficient nucleotide triplets to code for the appropriate number of amino acids in the polypeptide chains of a particular protein. In bacteria the coding sequences are continuous, but in higher organisms these coding sequences (exons) are interrupted by intervening sequences that are noncoding (introns) at various positions. Some genes code for RNA molecules, which will not be further translated into proteins. These code for functional ribosomal RNA (rRNA) and transfer RNA (tRNA), which play vital roles in polypeptide synthesis.
Transcription and Translation
The conversion of genetic information to polypeptides and proteins relies on the transcription of sequences of bases in DNA to mRNA molecules; mRNAs are found mainly in the nucleolus and the cytoplasm, and are polymers of nucleotides containing a ribose phosphate unit attached to a base (Fig. 1.3). RNA is a single-stranded molecule but it can hybridize with a complementary sequence of single-stranded DNA (ssDNA). Genetic information is carried from the nucleus to the cytoplasm by mRNA, which in turn acts as a template for protein synthesis. Each base in the mRNA molecule is lined up opposite to the corresponding base in the DNA: C to G, G to C, U to A, and A to T. A gene is always read in the 5′-3′orientation and at 5′ promoter sites, which specifically bind the enzyme.
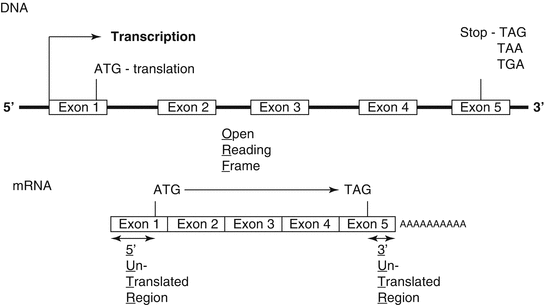
Fig. 1.3
The intronic and exonic structure of a gene coded on chromosomal DNA and the structural correspondence as a processed mRNA
RNA polymerase and so indicate where transcription is to commence. Eukaryotic genes have two AT-rich promoter sites. The first, the TATA box, is located about 25 bp upstream of (or before) the transcription start site, while the second, the CAAT box, is 75 bp upstream of the start site.
The initial or primary mRNA is a complete copy of one strand of DNA and therefore contains both introns and exons. While still in the nucleus, the mRNA undergoes posttranscriptional modification whereby the 5′and 3′ ends are protected by the addition of an inverted guanidine nucleotide (CAP) and a chain of adenine nucleotides (Poly A), respectively. In higher organisms, the primary transcript mRNA is further processed inside the nucleus, whereby the introns are spliced out. Splicing is achieved by small nuclear RNA in association with specific proteins. Furthermore, alternative splicing is possible whereby an entire exon can be omitted. Thus more than one protein can be coded from the same gene. The processed mRNA then migrates out of the nucleus into the cytoplasm. Polysomes (groups of ribosomes) become attached to the mRNA. Translation begins when the triplet AUG (methionine) is encountered. All proteins start with methionine, but this is often lost as the leading sequence of amino acids of the native peptides is removed during protein folding and posttranslational modification into a mature protein. Similarly the Poly A tail is not translated and is preceded by a stop codon, UAA, UAG, or UGA. The mRNA align on the endoplasmic reticulum and the ribosomal subunit synthesis the polypeptide chain in to the lumen of the ER.
The Control of Gene Expression
Gene expression can be controlled at many points in the steps between the translation of DNA to proteins (Fig. 1.4). Proteins and RNA molecules are in a constant state of turnover; as soon as they are produced, processes for their destruction are at work. For many genes transcriptional control is the most important point of regulation. Deleterious, even oncogenic, changes to a cell’s biology may arise through no fault in the expression of a particular gene. Apparent overexpression may be due to non-breakdown of mRNA or protein product.
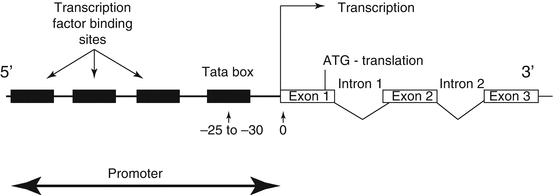
Fig. 1.4
Diagrammatic representation of the location of DNA binding sequence, which constitute the promoter recognition and assembly site in relationship to the site of gene transcription
Transcriptional Control
Gene transcription (DNA to mRNA) is not a spontaneous event and is possible only as a result of the interaction of a number of DNA-binding proteins with genomic DNA. Regulation of a gene’s expression must first start with the opening up of the double helix of DNA in the correct region of the chromosome. To do this, a class of protein molecules that recognize the outside of the DNA helix have evolved.
These DNA-binding proteins preferentially interact with the major groove of the DNA double helix. The base-pair composition of the DNA sequence can change the geometry of a DNA helix to facilitate the fi t of a DNA-binding protein with its target region: CG-rich areas form the Z-structure DNA helix; sequences such as AAAANNN cause a slight bend, and if this is repeated every 10 nucleotides it produces pronounced curves. DNA-binding proteins that recognize these distorted helices result either in the opening up of the helix so that the gene may be transcribed, or in the prevention of the helix being opened.
Structural Classes of DNA-Binding Proteins
The regulation of gene expression is controlled by DNA binding proteins. There are four basic classes of DNA-binding protein, classified according to their structural motifs: helix-turn-helix, zinc finger, helix-loop-helix, and leucine zipper.
Transcription Factors
The promoter is a modular arrangement of different elements that act as a binding site for RNA polymerase II and the initiation of transcription. The initiation of transcription involves a large complex of multimeric proteins [RNA polymerase (I or II)] plus the general transcription factors (GTFs). The GTFs can activate transcription of any gene that has a GTF recognition sequence such as the TATA box. The TATA box is a promoter element that is always located 25 to 30 base pairs from the start of transcription and serves to anchor RNA polymerase II.
Operators are proteins that bind to DNA sequences in the spatial areas where the large complex of proteins of the GTFs such RNA polymerase II complex assemble. Their mere presence stoichiometrically inhibits or enhances promoter protein assembly.
Enhancers are elements that can be at the 5ʹor the 3ʹ end of genes and can vary in distance from the coding sequence itself. Enhancers are not obligatory for the initiation of transcription but alter its efficiency in such a way as to lead to the upregulation of genes. Looping of the DNA helix allows distantly located enhancers to interact with the promoter site.
Transcription factors are proteins that bind to sequence specific regions of DNA at the 5′ end of genes called response elements to regulate gene expression. These elements can form a part of the promoters or enhancers. They can be divided into basal transcription factors, which are involved in the constitutive activation of so-called housekeeping genes, and inducible transcription factors, which are involved in the temporal and spatial expression of genes that underlie tissue phenotype and developmental regulation.
Insulators are DNA sequence elements which are the answer for the problem of enhancers inappropriately binding to and activating the promoter of some other gene in the same region of the chromosome as the target gene. Insulator binding regions of DNA (as few as 42 base pairs may do the trick) located between the enhancer(s) and promoter or silencer(s) and promoter of adjacent genes or clusters of adjacent genes. The function of the insulator protein is to prevent a gene from being influenced by the activation (or repression) of its neighbors.
The enhancer for the promoter of the gene for the delta chain of the gamma/delta T-cell receptor for antigen (TCR) is located close to the promoter for the alpha chain of the alpha/beta TCR (on chromosome 14 in humans). A T cell must choose between one or the other. There is an insulator between the alpha gene promoter and the delta gene promoter that ensures that activation of one does not spread over to the other.
All insulators discovered so far in vertebrates work only when bound by a protein designated CTCF (“CCCTC binding factor”; named for a nucleotide sequence found in all insulators). CTCF has 11 zinc fingers.
Genetic Disorders in Genitourinary Cancer
Normal cell growth and survival require genomic stability. One of the hallmarks of all neoplasms is genetic instability [35]. Gross chromosomal rearrangements (GCRs) such as translocations, deletions of a chromosome arm, interstitial deletions, inversions, and gene amplification have been consistently reported in different cancers [36]. Genomic instability in cells leads to the activation of proto-oncogenes or inactivation of tumor suppressor genes leading to transformation and development of cancer phenotypes (see below). Knowledge of the mechanism by which genome stability is maintained is crucial for the development of therapeutic applications in cancer management
Definitions of Chromosomal Disorders
Aneuploidy refers to the state of an abnormal number of chromosomes (differing from the normal diploid number). Abnormalities may occur in either the number or the structure of the chromosomes.
Abnormal Chromosome Numbers
Nondisjunction
If a chromosome or chromatids fail to separate either in meiosis or mitosis, one daughter cell would receive two copies of that chromosome and other cells receive no copies of the chromosome. Nondisjunction during meiosis can lead to an ovum or sperm having either [1] an extra chromosome (trisomic), resulting in three instead of two copies of the chromosome [e.g., trisomy 7 bladder and ureteral tumors [36, 37]]; or [2] no chromosome (monosomic), resulting in one instead of two copies of the chromosome. Full autosomal monosomies are extremely rare and deleterious. Sex chromosome trisomies (e.g., Klinefelter’s syndrome, XXY) are relatively common. The sex-chromosome monosomy in which the individual has an X chromosome only and no second X or Y chromosome is known as Turner’s syndrome. Occasionally, nondysjunction can occur during mitosis shortly after two gametes have fused. It will then result in the formation of two cell lines, each with a different chromosome complement. This occurs more often with the sex chromosome, and results in a mosaic individual. Rarely the entire chromosome set may be present in more than two copies, so the individual may be triploid rather than diploid and have a chromosome number of 69. Triploidy and tetraploidy (four sets) are nonviable.
Abnormal Chromosome Structures
Abnormal constitution of chromosomes can lead to the disruption to the DNA and gene sequences, giving rise to genetic diseases. Deletions of a portion of a chromosome may give rise to a disease syndrome if two copies of the genes in the deleted region are necessary, and the individual will not be normal with the one copy remaining on the nondeleted homologous chromosome. For example, Wilms’ tumor is characterized by deletion of part of the short arm of chromosome11.
Duplications occur when a portion of the chromosome is present on the chromosome in two copies, in that there is an extra set of chromosomes present.
Inversions involve an end-to-end reversal of a segment within a chromosome; e.g. abcdefgh becomes abcfedgh. Translocations occur when two chromosome regions join together, when they would not normally. Chromosome translocations in somatic cells may be associated with tumorigenesis.
Mitochondrial Chromosome Disorders
Most mitochondrial diseases are myopathies and neuropathies with a maternal pattern of inheritance. Other abnormalities include retinal degeneration, diabetes mellitus, and hearing loss.
Analysis of Chromosome Disorders
The analysis of gross chromosomal disorders has traditionally involved the culture of isolated cells in the presence of toxins such as colchicine. It arrests the cell cycle in mitosis, and with appropriate staining, the chromosomes with their characteristic banding can be identified and any abnormalities detected. New molecular biology techniques, such as yeast artificial chromosome (YAC)-cloned probes, have made it simpler and cover large genetic regions of individual chromosomes. These probes can be labelled with fluorescently tagged nucleotides and used in in situ hybridization of the nucleus of isolated tissue from patients, as in fluorescent in-situ hybridization (FISH). These tagged probes allow rapid and relatively unskilled identification of metaphase chromosomes, and allow the identification of chromosomes dispersed within the nucleus. Furthermore, tagging two chromosome regions with different fluorescent tags allows easy identification of chromosomal translocations.
Gene Defects
Mutations
Although DNA replication is a very accurate process, occasionally mistakes occur to produce changes or mutations. These changes can also occur due to other factors such as radiation, ultraviolet light, or chemicals. Mutations in gene sequences or in the sequences that regulate gene expression (transcription and translation) may alter the amino acid sequence in the protein encoded by that gene. In some cases protein function will be maintained; in other cases it will change or cease, perhaps producing a clinical disorder.
Point mutation involves the substitution of one nucleotide for another, thereby
changing the codon in a coding sequence. For example, the triplet AAA, which codes for lysine, may be mutated to AGA, which codes for arginine. Whether a substitution produces a clinical disorder depends on whether it changes a critical part of the protein molecule produced. Fortunately, many substitutions have no effect on the function or stability of the proteins produced, as several codons code for the same amino acid.
Insertion or deletion of one or more bases is a more serious change, as it results in the alteration of the rest of the following sequence to give a frame-shift mutation. For example, if the original code was TAA GGA GAG TTT and an extra nucleotide (A) is inserted, the sequence becomes TAA AGG AGA GTT T. Alternatively, if the third nucleotide (A) is deleted, the sequence becomes TAGGAG AGT TT. In both cases, different amino acids are incorporated into the polypeptide chain. This type of change is seen in some forms of thalassemia. Insertions and deletions can involve many hundreds of base pairs of DNA. For example, some large deletions in the dystrophin gene remove coding sequences, which results in Duchenne muscular dystrophy.
Splicing Mutations
If the DNA sequences that direct the splicing of introns from mRNA are mutated, then abnormal splicing may occur. In this case the processed mRNA, which is translated into protein by the ribosomes, may carry intron sequences, thus altering which amino acids are incorporated into the polypeptide chain.
Termination Mutations
Normal polypeptide chain termination occurs when the ribosomes processing the mRNA reach one of the chain termination or stop codons (see above). Mutations involving these codons result in either late or premature termination. For example, haemoglobin constant spring is a haemoglobin variant where, instead of the stop sequence, a single base change allows the insertion of an extra amino acid.
Single-Gene Disease
Monogenetic disorders involving single genes can be inherited as dominant, recessive, or sex-linked characteristics. Inheritance occurs according to simple mendelian laws, making predictions of disease in offspring and therefore genetic counselling more straightforward.
Autosomal Dominant Disorders
Autosomal dominant disorders (incidence, 7 per 1,000 live births) occur when one of the two copies has a mutation and the protein produced by the normal form of the gene is unable to compensate. In this case a heterozygous individual will manifest the disease. The offspring of heterozygotes have a 50 % chance of inheriting the chromosome carrying the disease allele, and therefore also of having the disease (as in polycystic kidney disease).
These disorders have great variability in their manifestation and severity. Incomplete penetrance may occur if patients have a dominant disorder that does not manifest itself clinically. This gives the appearance of the gene having skipped a generation. New cases in a previously unaffected family may be a result of a new mutation. If it is a mutation, the risk of a further affected child is negligible. Li-Fraumeni syndrome (LFS) is an autosomal dominant disorder associated with cancer predisposition syndrome. Affected individuals have a p53 mutation and have a predisposition to a number of malignancies including soft tissue sarcoma, breast cancer, leukemia, adrenocortical tumors, melanoma, and colon cancer [38]. Similarly, hereditary nonpolyposis colorectal carcinoma (HNPCC) is an autosomal dominant predisposition to develop colorectal, endometrial, ovarian, urinary tract, stomach, small bowel, and biliary tract carcinomas, as well as brain tumors (Lynch syndrome I and II) [39].
Autosomal Recessive Disorders
These disorders manifest themselves only when an individual is homozygous for the disease allele. In this case the parents are generally unaffected, healthy carriers (heterozygous for the disease allele). There is usually no family history, although the defective gene is passed from generation to generation. The offspring of an affected person will have healthy heterozygotes unless the other parent is also a carrier. If both parents are carriers, the offspring have a one in four chance of being homozygous and affected, a one in two chance of being a carrier, and a one in four chance of being genetically normal. Consanguinity increases the risk. The clinical features of autosomal recessive disorders are usually severe; patients often present in the first few years of life and have a high mortality. Many inborn errors of metabolism are recessive diseases.
Sex-Linked Disorders
Genes carried on the X chromosome are said to be X-linked, and can be dominant or recessive in the same way as autosomal genes. As females have two X chromosomes, they will be unaffected carriers of X-linked recessive diseases. However, since males have just one X chromosome, any deleterious mutation in an X-linked gene will manifest itself because no second copy of the gene is present.
Imprinting
It is known that normal humans need a diploid number of chromosomes—46. In some way the chromosomes are imprinted so that the maternal and paternal contributions are different. The expression of a gene depends on the parent who passed on the gene. Imprinting is relevant to human genetic disease because different phenotypes may result, depending on whether the mutant chromosome is maternally or paternally inherited. It has been suggested that DNA methylation may be the epigenetic marking for imprinting phenomenon in mammals [40]. DNA methylation is involved in the activation of tumor suppressor and other genes in prostate, renal, and bladder cancer. Loss of imprinting may be a primary event in Wilms’ and testicular tumors [41].
Complex Traits: Multifactorial and Polygenic Inheritance
Characteristics resulting from a combination of genetic and environmental factors are said to be multifactorial; those involving multiple genes can also be said to be polygenic. Measurements of most biological traits (e.g., height) show a variation between individuals in a population. This variability is due to variation in genetic factors and environmental factors. Environmental factors may play a part in determining some characteristics, such as weight, while other characteristics such as height may be largely genetically determined. This genetic component is thought to be due to the additive effects of a number of alleles at a number of loci, many of which can be individually identified using molecular biological techniques [42].
Cancer Cell Biology and Genetics
Cancer cells are a clonal population of cells in which the accumulation of mutations in multiple genes has resulted in escape from the normally strictly regulated mechanisms that control growth and differentiation of somatic cells. The malignant phenotype acquired by cancer cells has the following properties [43]:
1.
Loss of growth control
2.
Resistance to apoptosis
3.
Ability to create new blood supply (angiogenesis)
4.
Infiltration into the surrounding tissues
5.
Metastasis: ability to colonize and survive in an ectopic environment
The process of oncogenesis can be thought of as a stepwise process, with mutations in particular genes being required for progression from one phase to another, that is, from transformed cell to metastatic cell; these gene mutations are rate-limiting. Rarely, if ever, is a single event responsible for conversion of a normal cell to a malignant cell. Mutations may be a combination of inherited, spontaneous, and environmentally induced factors. Oncogenes are mutated genes that cause normal cell to grow out of control and become cancer cells.
Tumor suppressor genes slow down cell division, repair DNA, and induce apoptosis. Often several oncogenes may be found within the same receptor-signalling pathway (Fig. 1.5).
 < div class='tao-gold-member'>
< div class='tao-gold-member'>
 Diet and GU Cancers
Diet and GU Cancers
 Life After Urological Cancer – Psychological Issues
Life After Urological Cancer – Psychological Issues
 Genetics and Genito-Urinary Cancer
Castrate Resistant Prostate Cancer: Systemic Chemotherapy and a System Problem
Genetics and Genito-Urinary Cancer
Castrate Resistant Prostate Cancer: Systemic Chemotherapy and a System Problem
 Renal Failure, Dialysis and Transplantation: In the Management of Renal Cell Carcinoma (Solitary Kidney and Bilateral Renal Tumours)
Renal Failure, Dialysis and Transplantation: In the Management of Renal Cell Carcinoma (Solitary Kidney and Bilateral Renal Tumours)
 High Intensity Focused Ultrasound (Hifu) in Prostate Cancer
High Intensity Focused Ultrasound (Hifu) in Prostate Cancer




Only gold members can continue reading. Log In or Register to continue
Related posts:
Diet and GU Cancers
Life After Urological Cancer – Psychological Issues
Genetics and Genito-Urinary Cancer
Castrate Resistant Prostate Cancer: Systemic Chemotherapy and a System Problem
Renal Failure, Dialysis and Transplantation: In the Management of Renal Cell Carcinoma (Solitary Kidney and Bilateral Renal Tumours)
High Intensity Focused Ultrasound (Hifu) in Prostate Cancer
Stay updated, free articles. Join our Telegram channel
Full access? Get Clinical Tree
